Why This Matters for Enterprise AI
A prompt chain runs in a straight line. Step one, then step two, then step three, every time, in the same order, no matter what the input is. That works until two things happen. First, the inputs stop looking alike: a support queue holds billing questions, bug reports, and refund demands, and forcing all three down one pipeline makes every answer mediocre. Second, the chain gets slow, because steps that could run at the same time are waiting in line for no reason.
Routing and parallelization are the two patterns that fix this. Routing decides where an input should go. Parallelization decides what can happen at once. If prompt chaining is the straight line, these two patterns are the fork and the fan-out, and together they are how an agent system scales past a single happy path without losing accuracy or making the user wait.
What Are Routing and Parallelization?
Routing is the practice of having a model or classifier inspect an incoming request and dispatch it to the most appropriate specialized path, sub-agent, or tool. Antonio Gulli, in Agentic Design Patterns, frames routing as the pattern that introduces conditional logic into agent workflows: instead of one handler trying to be good at everything, a router sends each input to a handler built for exactly that kind of input.
Parallelization is the practice of running independent sub-tasks concurrently rather than one after another, then combining the results. It comes in two flavors. Sectioning splits a single task into independent chunks, runs them at the same time, and aggregates the pieces. Voting runs the same task several times and takes a consensus from the answers.
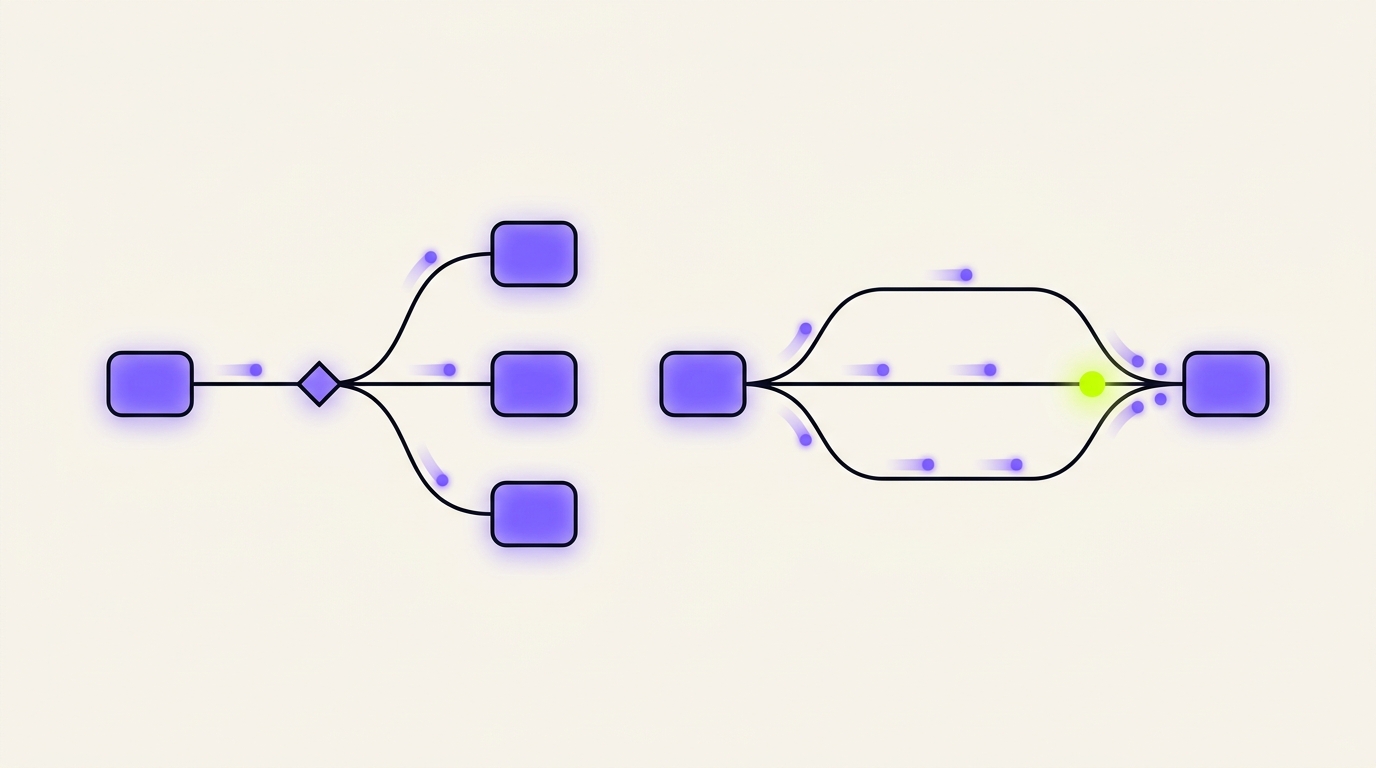
The two patterns solve different problems and pair well. Routing buys you accuracy through separation of concerns: each handler stays narrow, so it stays sharp. Parallelization buys you latency and robustness: independent work finishes in the time of the slowest piece, not the sum of all pieces. The previous pattern in this series, prompt chaining, warned that naive sequential chains give away latency. Parallelization is how you claw it back.
How Routing Works
A router sits at the front of the workflow and answers one question: given this input, which path handles it best? The mechanics come down to four moves.
- Define the routes. List the distinct paths an input could take. For a customer-service agent that might be
billing,technical_support,refund, andgeneral. Each route points at a sub-agent, a prompt, or a tool tuned for that category. - Classify the input. Use an LLM call, a smaller fine-tuned classifier, or a plain embedding-similarity lookup to label the request. The classifier's only job is to pick a route, so it can be cheap and fast.
- Dispatch to the handler. Hand the request to the chosen path. That handler now works with focused instructions and a narrow remit, which is exactly what makes its output reliable.
- Return the result, with a fallback. The handler answers. If the router is unsure, it falls back to a safe default route or escalates rather than guessing.
The accuracy gain is the whole point. A single prompt that tries to handle billing math, debugging steps, and refund policy at once carries instructions that pull against each other. Split those into routed handlers and each one keeps a tight, conflict-free prompt. Routing is also the connective tissue of multi-agent systems, where a coordinator routes work to specialist agents instead of one agent attempting everything.
Code Example (Abbreviated)
Here is a router in LangGraph. A cheap classification call labels the request, and a conditional edge sends it to the matching specialist node.
# Abbreviated: illustrative LangGraph router, not production code
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-4o-mini")
def classify(state):
label = llm.invoke(
f"Classify into billing, technical, or refund:\n{state['query']}"
).content.strip().lower()
return {"route": label}
def route(state):
# Map the label to a node; unknown labels fall back to 'general'
return state["route"] if state["route"] in {
"billing", "technical", "refund"} else "general"
graph = StateGraph(dict)
graph.add_node("classify", classify)
graph.add_node("billing", billing_agent)
graph.add_node("technical", technical_agent)
graph.add_node("refund", refund_agent)
graph.add_node("general", general_agent)
graph.set_entry_point("classify")
graph.add_conditional_edges("classify", route) # dispatch by label
for handler in ["billing", "technical", "refund", "general"]:
graph.add_edge(handler, END)
The same shape exists in Google ADK, where an LlmAgent with sub-agents can delegate by transferring control to the child whose description matches the request. The framework changes; the dispatch-by-classification idea does not.
How Parallelization Works
Parallelization assumes the opposite of a chain: that the next piece of work does not depend on the last. When that holds, you run the pieces concurrently and merge them. The two flavors handle two different situations.
Sectioning splits one task into independent sub-tasks. To summarize a 200-page document, you do not feed it through one call. You section it into chapters, summarize each chapter in parallel, then combine the chapter summaries into a final pass. Each section is independent, so the wall-clock time is roughly the time of the single slowest section instead of the sum of all of them.
Voting runs the same task multiple times and aggregates the answers. Ask a model to flag whether code contains a security vulnerability, run that check five times, and take the majority verdict. Voting trades cost for confidence: you pay for N calls to reduce the chance that one unlucky generation decides a high-stakes answer on its own.
Both flavors share the same skeleton: fan out the independent work, gather the results, aggregate. The aggregation step is where the real design lives. For sectioning you concatenate, merge, or run a final synthesis call. For voting you pick majority, unanimity, or a weighted scheme. Anthropic's Building Effective Agents treats both sectioning and voting as the canonical parallelization workflow, and the reason is plain: independent sub-tasks have no business waiting in line.
# Abbreviated: parallel fan-out then gather (sectioning)
import asyncioasync def summarize(section):
return await llm.ainvoke(f"Summarize:\n{section}")
async def run(sections):
# Fan out: every section runs at once
parts = await asyncio.gather(*(summarize(s) for s in sections))
# Gather: one final pass combines the pieces
return await llm.ainvoke("Combine these summaries:\n" + "\n".join(
p.content for p in parts))
Enterprise reality: A compliance team needs every clause in a 90-page contract checked against a policy rulebook. Run sequentially, that is a coffee-break wait per review. Section the contract by clause, fan the checks out concurrently, and the same review returns in seconds, because the slow part runs in parallel instead of in series. For the handful of clauses that carry legal risk, layer voting on top: run the high-risk check three times and require agreement before the system flags it, so one stray generation never triggers a false alarm on its own.
The Tradeoffs You Are Buying
Neither pattern is free. Each solves one problem and introduces another you have to plan for.
Routing's risk is misclassification. The router is a single point of failure at the front of the workflow. Send a refund request to the technical-support path and every downstream step is now confidently working on the wrong job, which is worse than a slightly generic answer would have been. The defenses are a confidence threshold that triggers a fallback when the router is unsure, a catch-all general route so nothing dead-ends, and logging every routing decision so you can see what gets miscategorized and retune. Keep the route list short, too. A router choosing between four clear categories is far more reliable than one juggling twenty overlapping ones.
Parallelization's risk is cost and aggregation logic. Voting multiplies your token bill by N for the same answer, so reserve it for decisions where a wrong call is expensive. Aggregation is the subtler trap: combining parallel results is its own problem, and a sloppy merge can undo everything the fan-out bought. Concatenated section summaries can contradict each other; a voting scheme has to define what happens on a tie. The work you saved on latency you partly spend on writing a merge step that holds up.
A quieter failure mode spans both patterns: parallelizing or routing work that was never independent in the first place. If section two depends on the output of section one, running them concurrently produces garbage, and no clever aggregation saves it. Reach for these patterns when the structure of the problem actually branches or splits, not because concurrency sounds fast.
When to Use Each (and When Not To)
Routing earns its place when inputs are heterogeneous and a specialist beats a generalist.
- Use it when requests fall into distinct categories that each deserve a tuned handler: support triage, query-complexity tiers (cheap model for easy questions, strong model for hard ones), or language-based dispatch.
- Skip it when every input wants the same treatment. A router in front of a single uniform task is pure overhead and one more thing to misclassify.
Parallelization earns its place when work is independent and you care about wall-clock time or robustness.
- Use sectioning when a task splits cleanly into chunks that do not depend on each other, and you want the result back in the time of the slowest chunk.
- Use voting when accuracy on a single high-stakes decision matters more than the extra cost of running the check several times.
- Skip both when sub-tasks are sequential. If step two needs step one, that is a job for prompt chaining, not a fan-out.
The honest test mirrors the one for chaining. Routing should make answers more accurate, and parallelization should make them faster or more reliable. If a router is not separating meaningfully different inputs, or a fan-out is not running independent work, you have added moving parts without buying anything.
Key Takeaways
- Routing inspects an input and dispatches it to the most appropriate specialized path, sub-agent, or tool, so each handler stays narrow and accurate through separation of concerns.
- Parallelization runs independent sub-tasks concurrently: sectioning splits one task into independent chunks and aggregates them, while voting runs the same task N times and takes a consensus.
- Routing buys accuracy; parallelization buys latency and robustness. They pair naturally on top of a prompt chain.
- The tradeoffs are real: routing can misclassify (use confidence thresholds and a fallback route), and parallelization adds cost plus the burden of getting the aggregation step right.
- Use routing when inputs are heterogeneous, parallelization when work is independent, and neither when the task is a single sequential pipeline. Up next, reflection and adaptation adds the self-correction loop that makes these workflows improve on their own output.