On May 7, 2026, Google stopped showing FAQ rich results in Search. The accordion of questions that used to sit under your listing, the extra space, the click-through bump: all gone. The feature that launched a thousand "add FAQ schema for more SERP space" posts disappeared without an explanation from Google.
FAQ schema, the FAQPage structured data that marks up a list of questions and their answers so machines can read them, now matters more than it did when the rich result was alive. It just matters for a different reader: not Google's blue links, but the AI systems that answer a growing share of your audience's questions before anyone reaches a results page.
Most FAQ schema guides still sell you the dead feature. This one covers the live one. I will go through what changed and what large language models actually do with your FAQ schema, which is not what most vendors claim. Then I will show, with working code, how to implement FAQPage schema so ChatGPT, Perplexity, and Google's AI Overviews pull your answers into theirs.
The feature everyone optimized for is gone
The timeline explains why so much published advice is now wrong.
In August 2023, Google restricted FAQ rich results to "well known, authoritative government and health websites." The rest of us lost the SERP feature overnight. Most people missed it, because the schema stayed valid and the markup kept validating clean.
Then on May 7, 2026, Google removed them for good. FAQ rich results stopped appearing for everyone. The tooling is being retired on a schedule: the Search Console rich result report and the Rich Results Test drop FAQ support through June 2026, and the Search Console API ends its FAQ support in August 2026. Google added a deprecation notice to its docs and said nothing more.
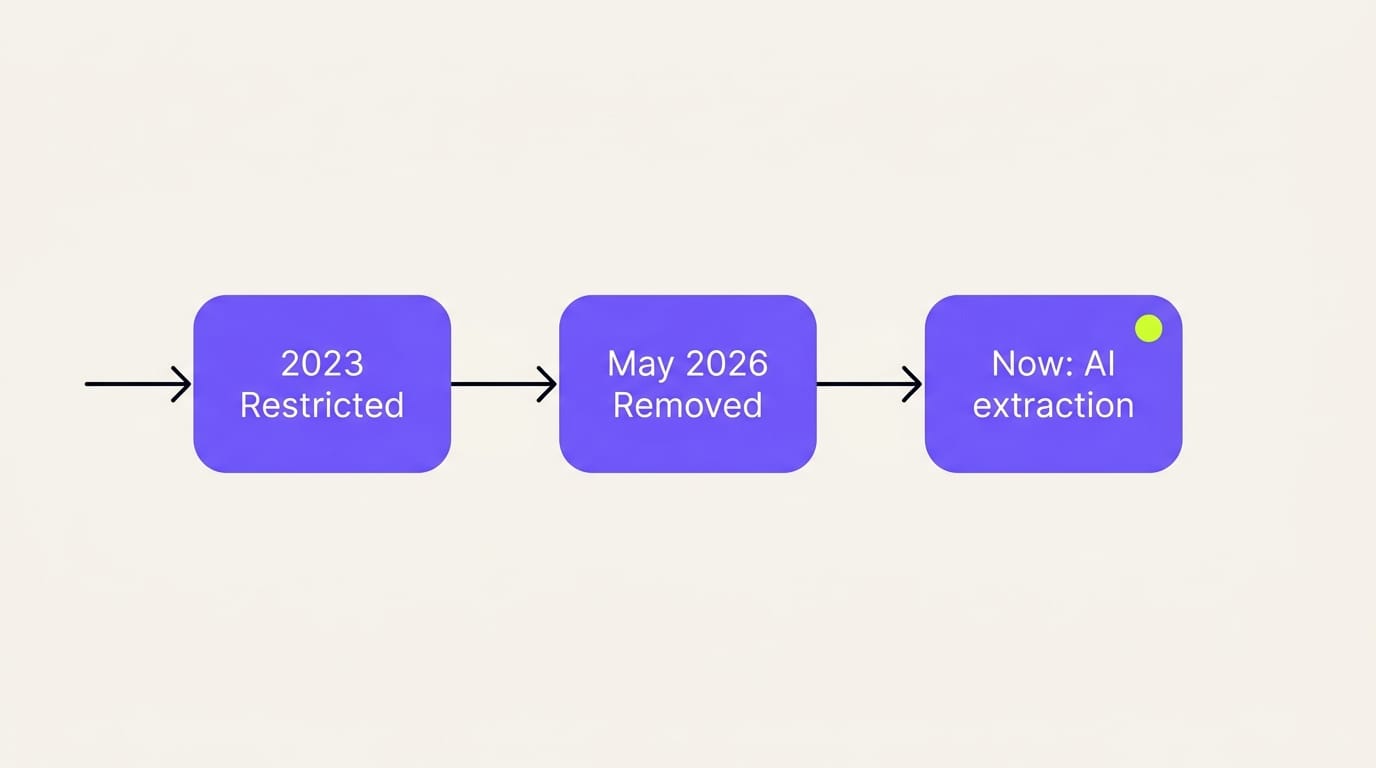
Your existing FAQ schema is not a problem, though. Google has long held that unused structured data does not hurt a page, and FAQPage is still a valid Schema.org type. You do not need to rip it out. You need to know what it does now.
So why does FAQ schema still matter?
Because the question-and-answer format is the most extractable shape of content on the web, and extraction is the whole game in AI search. A clean FAQ schema hands the machines a running start.
When someone asks ChatGPT or Perplexity a question, the system does not read your page the way a person does. It reads in fragments, breaking the text into chunks, ranking them for relevance, then stitching the strongest ones into an answer with citations. A question followed immediately by its answer is already shaped like the output it wants, so you have done the chunking for it.
That is why FAQ schema content shows up so often in AI answers, and the reason is the structure rather than anything in the markup itself. The gap between those two is where almost every FAQ schema guide goes wrong next.
What AI actually does with your schema
Large language models do not parse your JSON-LD as structured data. They read it as text.
Schema markup is built to be machine-readable in a formal sense, a labeled set of key-value pairs a parser can interpret, and Google's traditional systems use it that way. LLMs do not. When a model tokenizes your page, the JSON-LD inside your