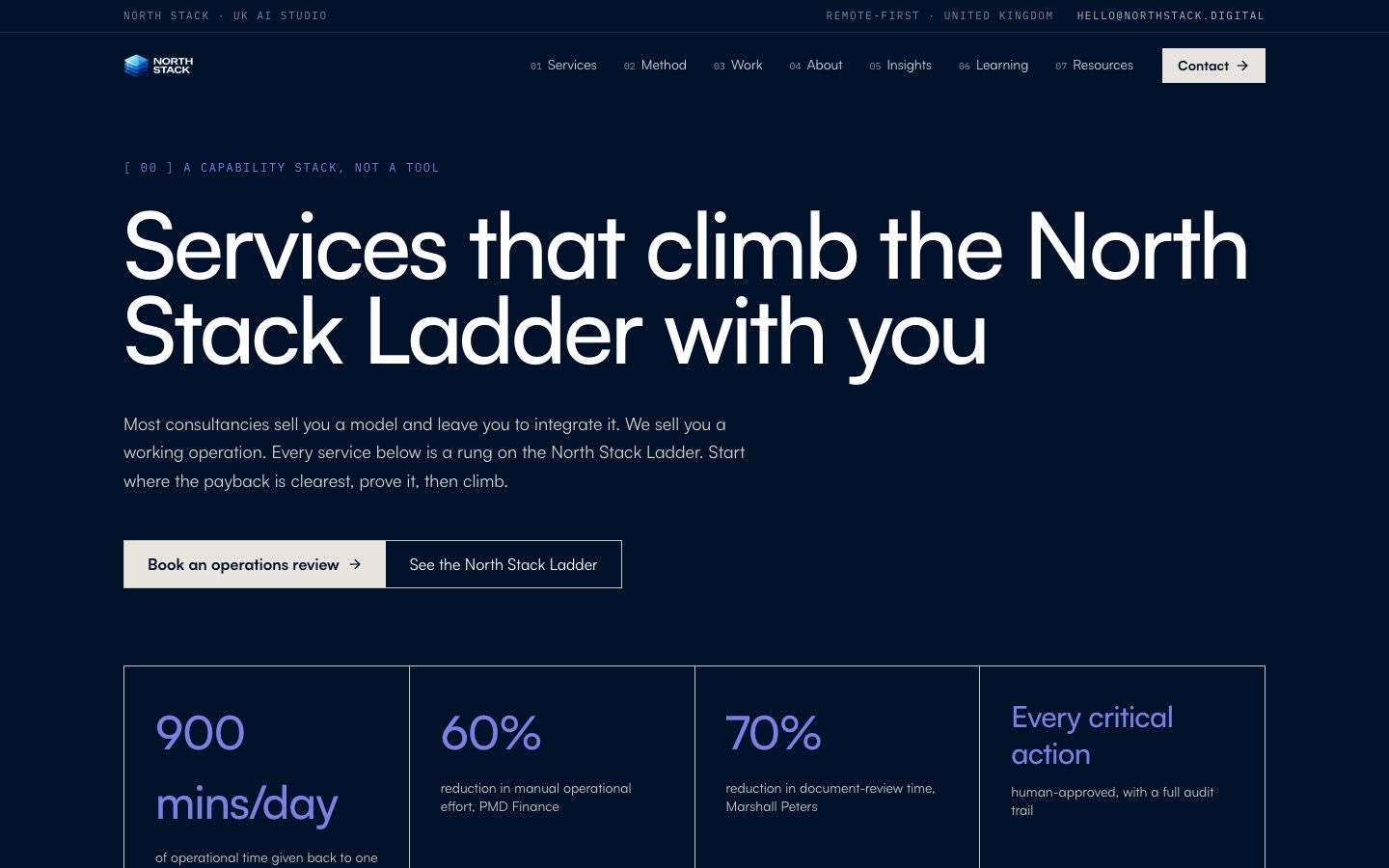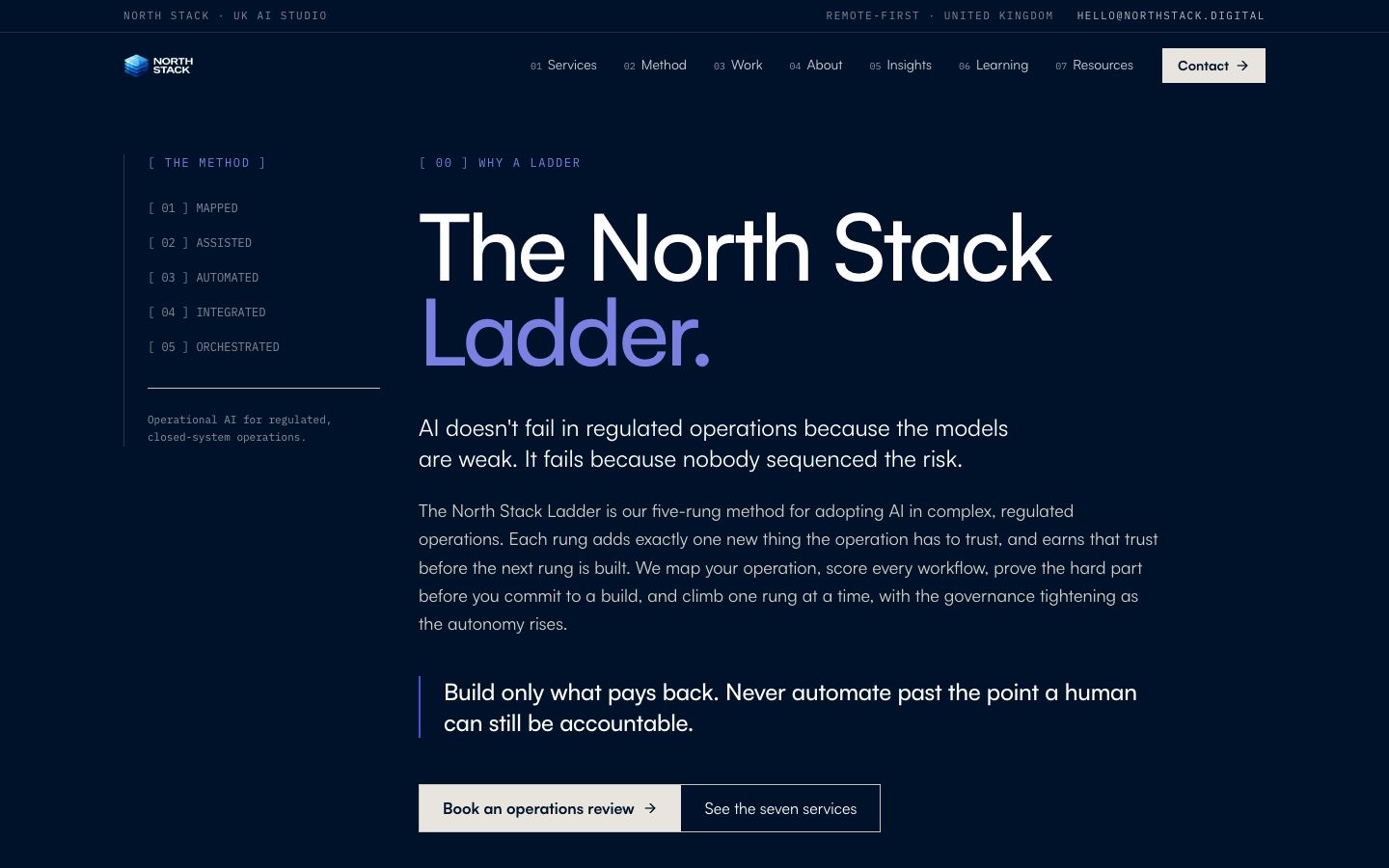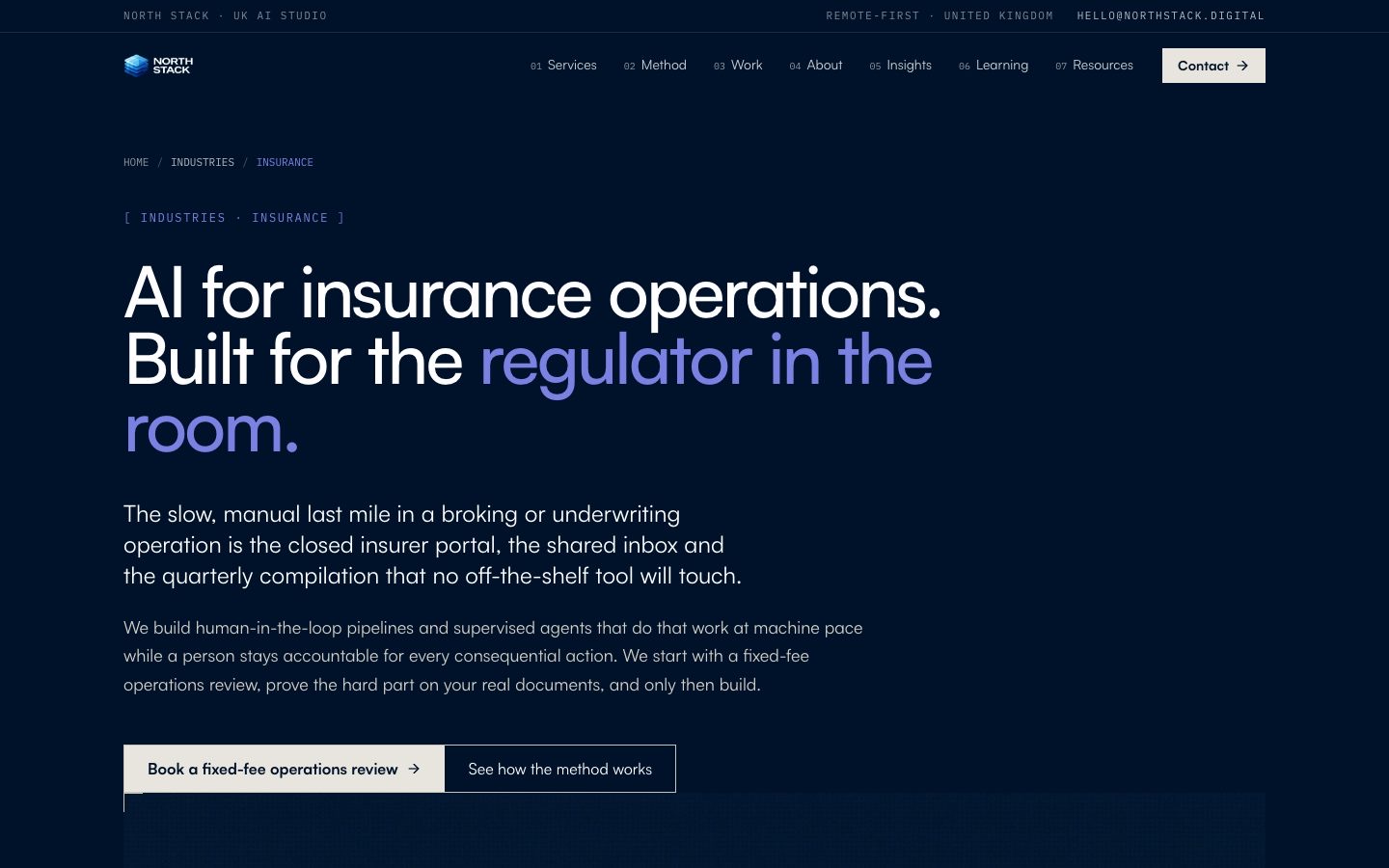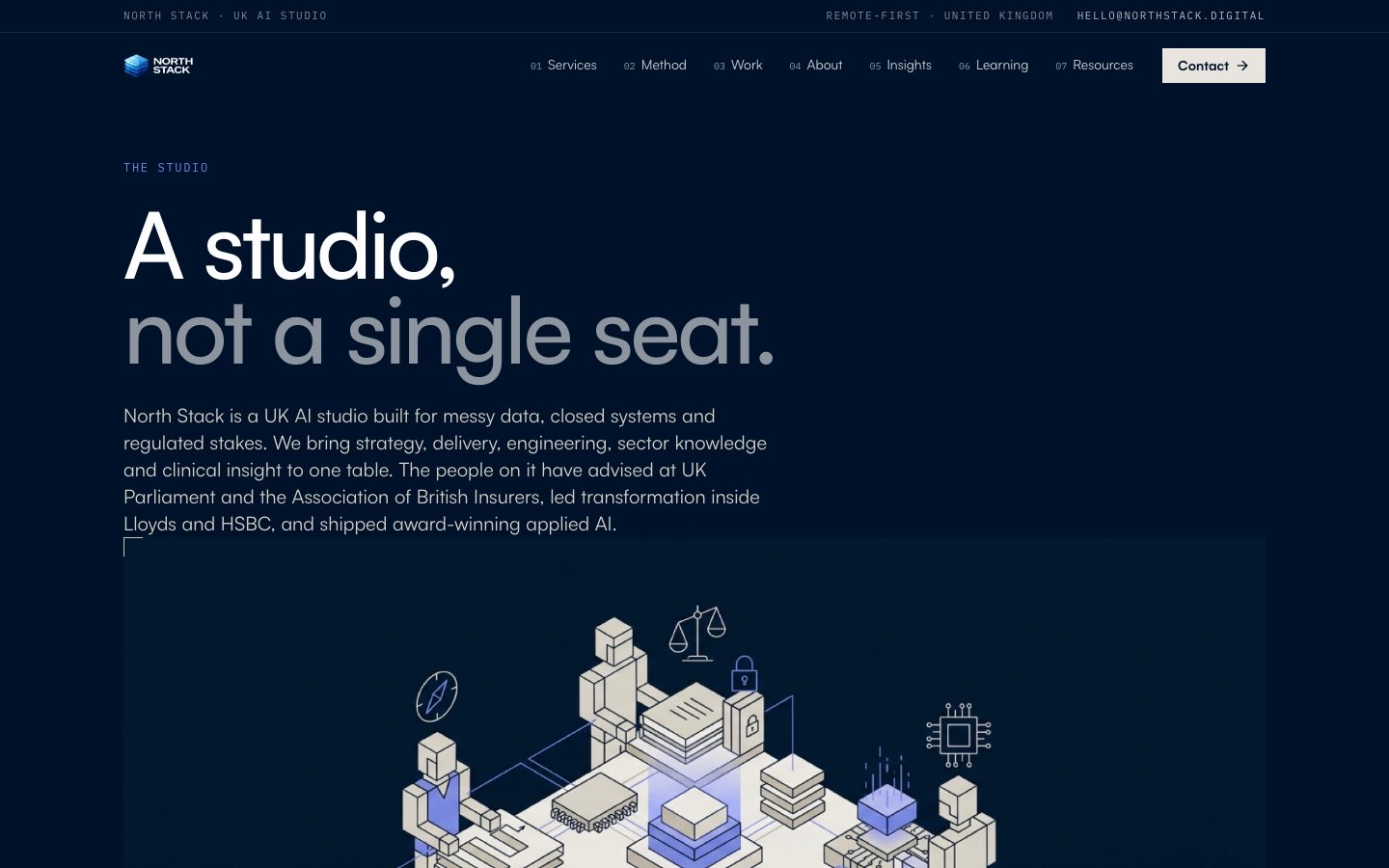




North Stack is a UK AI studio that builds automation for regulated operations, the document processing, claims, and reporting work that off-the-shelf software won't touch. Their team comes out of UK Parliament, Lloyds, HSBC, and the Association of British Insurers, and their client work is serious. Their website was not. When we looked at it, it was a six-page Lovable single-page app that looked clean and did almost none of the job a website is supposed to do.
The problems were the kind you can't see from the front end, which is the worst kind. The contact form didn't send anywhere; clicking submit tried to open the visitor's email client, so on a phone or a locked-down work laptop it did nothing at all. The newsletter box showed a thank-you and then discarded the address, with a line in the code that quietly admitted as much. The site rendered entirely in the browser, so every page handed Google and every AI assistant the same empty shell and trusted their code to fill it in later, which a lot of crawlers never do. There was one schema block on the homepage and none anywhere else, no sitemap, no llms.txt, and the social-share image pointed at a staging domain that had stopped existing. Broken links returned a 200 instead of a 404. Six pages, and most of the proof the business had spent two years earning sat behind a blank page as far as a machine was concerned.
We didn't reskin it. We rebuilt the foundation, then put the brand on top. The new site runs on TanStack Start and React 19 as a server-rendered application on Cloudflare Workers, so a finished page streams from the edge before any browser code runs, for a person or a crawler or an agent alike. Six pages became thirty-four indexable URLs: a services hub with seven service pages, five case studies each on their own address, four industry landing pages, a methodology page, a working blog, and the legal pages a regulated buyer checks before they trust anyone. The contact form posts to a real backend behind Cloudflare Turnstile and sends back a confirmation. Structured data went from one type to more than eight, including per-author Person schema that ties each article to a named expert.
The part we're proudest of is the part almost nobody is building yet. We made the whole site readable by AI agents, what's becoming known as answer-engine optimisation: a Content-Signal directive in robots.txt, RFC 8288 Link headers on every response, an llms.txt index of the site, and a build-time markdown version of all thirty-four pages, served the moment a client sends an Accept: text/markdown header. The old site gave AI assistants nothing. The new one hands them the whole site, ready to read, which matters more every quarter as regulated buyers start their research inside ChatGPT, Perplexity, and Claude rather than Google.
For anyone who wants to know how much work this actually is: the rebuild touched 162 files and added a little over 14,000 lines, and the migration commit alone retired around 8,000 lines of the old app. It runs across 21 route templates and 81 components, with more than 30 bespoke isometric illustrations generated from a single locked visual recipe so every page reads as the same company. The before-and-after below walks through it, page by page.